
Le magazine de technologie du MIT, le MIT Technology Review, rapporte une étude de l’École Polytechnique Fédérale de Lausanne à propos de la manière dont sont entraînées les intelligences artificielles. Elles seraient de plus en plus entraînées… par d’autres intelligences artificielles. La faute à une rémunération des travailleurs trop faible, encouragés à automatiser leurs tâches.
Pour être fiable, l’IA a besoin d’être entraînée
Rappelons comment les modèles d’intelligence sont entraînés. Vous le savez sûrement, ils ont besoin de quantités gigantesques de données. Cependant, toutes les données ne se valent pas : elles doivent être les plus précises et les plus fiables, puisqu’elles déteindront sur les capacités de l’IA finale.
Comme le rappelle le MIT Technology Review, « de nombreuses entreprises rémunèrent des travailleurs occasionnels sur des plateformes », en prenant l’exemple de Mechanical Turk d’Amazon, la plus connue. Résolution de Captcha, étiquetage de données ou annotations de texte : autant de « micro-tâches » à réaliser, le plus souvent par des habitants de pays pauvres ou en voie de développement. Un mode de travail mis en avant notamment par Antonio Casilli dans son ouvrage En attendant les robots.
Pour gagner plus, il faut travailler plus vite : la solution, c’est l’IA
Ces travailleurs sont payés à la tâche, quelques centimes à chaque fois. Pour arriver à un taux horaire convenable, ils sont incités à faire au plus vite. Pour comprendre les mécaniques d’entraînement, 44 personnes ont été engagées par une équipe de chercheurs de l’École Polytechnique Fédérale de Lausanne via la plateforme Mechanical Turk afin de résumer 16 extraits d’articles de recherche médicale.
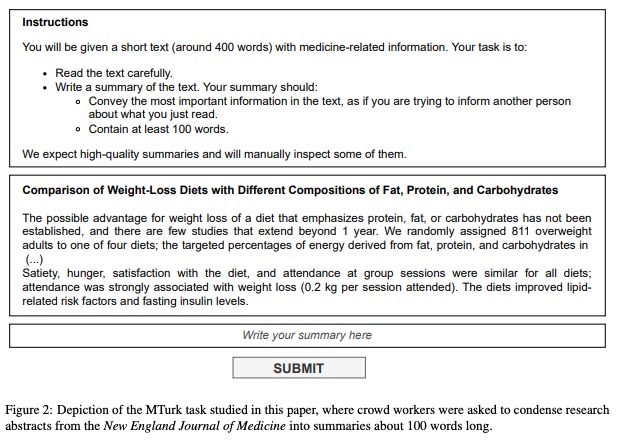
Les chercheurs ont analysé les résumés produits à l’aide d’un modèle d’IA formé par leurs soins, conçu pour déterminer si un texte a été généré ou non par ChatGPT. Les signes sont divers : des formes de phrases similaires, un manque de variété dans le choix des mots. On apprend également qu’ils ont vérifié les frappes de clavier pour savoir si les travailleurs engagés avaient copié-collé leurs résumés.

L’estimation résultante est qu’entre 33 et 46 % des 44 travailleurs auraient recouru à des modèles de générations de texte comme ChatGPT d’OpenAI. Pour les chercheurs Veniamin Veselovsky, Manoel Horta Ribeiro et Robert West, ce pourcentage pourrait augmenter dans les années à venir, les IA devenant de plus en plus puissantes et de plus en plus accessibles. Le coauteur Robert West a précisé sa pensée : « Je ne pense pas que ce soit la fin des plateformes de crowdsourcing. Cela change simplement la dynamique. »
Pourquoi la revalorisation du travail d’entraînement des IA est nécessaire
Le problème avec cette utilisation de ChatGPT dans l’entraînement d’IA, c’est que cela pourrait progressivement entraîner des erreurs dans les modèles, déjà sujets à des erreurs, on le constate extrêmement bien avec ChatGPT ou Midjourney.
[see_more slots= »1648629
Pour le chercheur en informatique de l’université d’Oxford Ilia Shumailov, « les erreurs peuvent être absorbées par ces modèles et amplifiées au fil du temps, ce qui rend leur origine de plus en plus difficile à déterminer ». Midjourney pourrait à terme devenir moins performant, puisqu’il se base sur des images publiées sur Internet. Seulement voilà : à cause de son succès, de très nombreuses images générées par lui-même sont apparues sur Internet. Même chose pour ChatGPT et les outils de génération de texte : se basant sur des contenus en ligne, ils génèrent des textes qui sont amenés à être publiés. Le serpent qui se mord la queue, en somme.

L’étude susmentionnée montre la nécessité de vérifier si des données ont été produites par une IA ou par un humain, et ce, d’autant plus sur des plateformes d’entraînement. Les contrôles de ces dernières devraient alors être renforcés et les entreprises d’IA auraient davantage intérêt à internaliser cette phase d’entraînement. Un mode de sous-traitance qui a pour conséquence l’exploitation de travailleurs pauvres : c’est ce qu’avait démontré une enquête du Time en janvier dernier. Des travailleurs kényans étaient payés moins de deux dollars de l’heure pour entraîner des modèles d’IA développés par OpenAI.
Du côté du sociologue Antonio Casilli, le problème est assez simple : « Si un système est construit sur l’exploitation et la sous-rémunération des travailleurs, il est toujours vulnérable à la « tricherie ». » Selon lui, il est « inutile de bannir les outils de génération de texte. Nous devons payer des salaires décents et reconnaître le statut des travailleurs. » Il se montre favorable à la généralisation du statut de salarié et non de travailleur indépendant pour ceux qui entraînent des IA, notamment sur des plateformes spécialisées.
Si vous voulez recevoir les meilleures actus Frandroid sur WhatsApp, rejoignez cette discussion.

Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et .
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.